
Tenant Data Isolation: Patterns and Anti-Patterns
Explore effective patterns and pitfalls of tenant data isolation in multi-tenant systems to enhance security and compliance.
Jul 30, 2025
Read More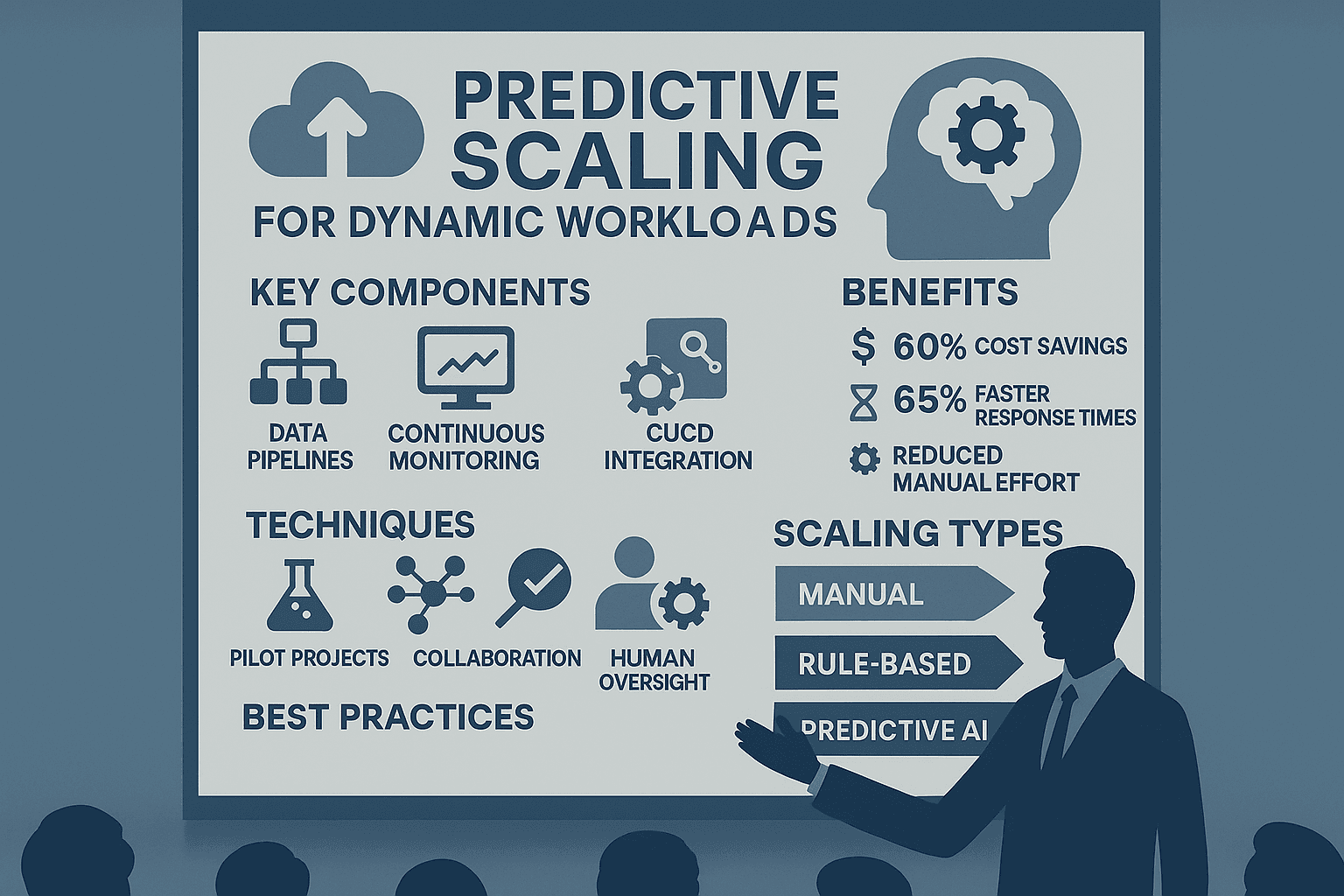
Managing cloud resources effectively is tough when workloads fluctuate. Traditional scaling methods often react too late or waste resources. AI-driven predictive scaling solves this by forecasting demand and adjusting resources in advance. Here’s what you need to know:
Quick Comparison: Scaling Methods
| Scaling Method | Pros | Cons | Best For |
|---|---|---|---|
| Manual Scaling | Simple, no setup required | Slow, prone to errors | Small, predictable workloads |
| Rule-Based | Automates basic thresholds | Limited flexibility, needs updates | E-commerce, SaaS platforms |
| Predictive (AI) | Proactive, handles complex patterns | Needs ML expertise, higher setup cost | Streaming, real-time apps |
| Hybrid AI | Combines reactive and predictive | Complex initial setup | Large-scale enterprise systems |
Predictive scaling isn’t just about saving money - it’s about keeping systems reliable, fast, and ready for growth. Ready to future-proof your DevOps strategy? Let’s dive in.
Creating an effective AI-driven predictive scaling system involves connecting three key elements. Together, they transform raw data into smart scaling decisions, ensuring applications stay responsive and efficient.
At the heart of predictive scaling are data pipelines. These pipelines gather and process essential metrics like CPU usage, memory, network activity, and user behavior. They adapt dynamically to workload changes while running automated quality checks to ensure data accuracy. By continuously monitoring these pipelines, anomalies can be detected early, and issues corrected quickly, minimizing the need for manual fixes. This constant flow of reliable data sets the foundation for improving system performance over time.
Real-time monitoring is crucial for understanding how applications perform, how healthy the infrastructure is, and how users interact with the system. It identifies performance bottlenecks and scaling inefficiencies as they happen, allowing teams to adjust models and address issues quickly. Automation plays a big role here, with real-time alerts and dashboards reducing manual effort and speeding up responses. These feedback loops also naturally tie into CI/CD pipelines, helping refine processes and improve scaling strategies.
Bringing predictive scaling into CI/CD pipelines connects resource management with application delivery. AI tools analyze these pipelines, convert them into clear, declarative formats, and flag inconsistencies. Predictive autoscaling leverages AI to anticipate demand spikes, enabling systems to prepare capacity in advance. AI agents also enhance system reliability by spotting infrastructure changes, enforcing policies, and generating templates that ensure compliance while cutting down on manual work. Examples of this integration include using declarative control planes and GitOps workflows, where tools like Terraform and Helm store configurations in Git alongside application code. This approach ensures deployments are version-controlled and tightly linked with scaling decisions. By embedding predictive scaling into the entire deployment process, teams can handle fluctuating loads while boosting developer efficiency, operational effectiveness, and cost control.
Machine learning is reshaping how DevOps teams manage fluctuating workloads by predicting resource needs before they arise. These techniques help forecast demand, optimize resource allocation, and reduce costs. By understanding these methods, teams can select the best approach tailored to their workload patterns. Importantly, these methods align well with the broader DevOps practices discussed earlier.
Time series forecasting uses historical data to anticipate future resource demands, making it an excellent choice for identifying daily or weekly traffic trends.
Choosing between ARIMA and LSTM depends on workload characteristics - ARIMA suits steady, predictable patterns, while LSTM excels in more complex, dynamic scenarios. For example, Google Cloud's Compute Engine requires at least three days of CPU-based autoscaling history to start generating predictions and uses up to three weeks of data for model training.
Anomaly detection identifies deviations from normal workload patterns, enabling systems to address potential bottlenecks proactively. This is particularly useful for unexpected events like flash sales or system failures that cause sudden demand surges.
Both supervised and unsupervised learning methods can be applied:
Combining these approaches creates a robust system for triggering automated alerts and scaling resources preemptively.
Reinforcement learning takes a dynamic approach by optimizing scaling policies through real-time learning. These algorithms analyze the outcomes of previous scaling actions and adapt policies based on factors like response times, resource costs, and user experience.
For example, the DTSALA algorithm effectively distributes jobs across system resources, improving load balancing and optimizing resource usage. This method supports gradual scaling adjustments through continuous monitoring.
Here's a quick comparison of these ML techniques:
| Technique | Best Use Case | Key Advantage |
|---|---|---|
| ARIMA | Predictable, seasonal patterns | Fast, lightweight processing |
| LSTM | Complex, non-linear workloads | Handles long-term dependencies |
| Anomaly Detection | Unexpected spikes and incidents | Proactive issue prevention |
| Reinforcement Learning | Dynamic, changing environments | Continuous improvement |
The accuracy of predictive scaling depends heavily on the quality and variety of data fed into these models. Regularly retraining models and maintaining high-quality data are critical to ensuring scaling decisions remain effective as applications and demand patterns evolve.
For teams aiming to integrate predictive scaling into their DevOps practices, Propelius Technologies offers tailored solutions to tackle dynamic workload challenges. Leveraging these machine learning techniques can significantly enhance the efficiency and adaptability of DevOps operations.
Taking a strategic approach to predictive scaling is essential. Starting small allows you to minimize risks and build confidence through measurable success. Pilot projects are a great way to test the waters before scaling up.
The smartest way to introduce predictive scaling is by focusing on pilot projects that showcase tangible benefits. Instead of diving into a company-wide rollout, begin with smaller, manageable initiatives that can demonstrate clear value.
Before launching, set specific success metrics. For example, you might aim to cut infrastructure costs by 20% or improve response times by 15%. These key performance indicators (KPIs) provide a clear way to measure progress and justify further investment.
Getting executive buy-in early is also crucial. A strong advocate within leadership can help secure the resources and support needed, especially when challenges arise.
By clearly defining outcomes and managing expectations, successful pilot projects can lay the groundwork for broader implementation. These early wins build trust and momentum, making it easier to scale predictive scaling efforts across the organization.
Predictive scaling thrives when silos between teams are broken down. Collaboration between development, operations, security, and data science teams is essential, as each group brings unique expertise to the table.
Empower these cross-functional teams to make decisions quickly. Developers, operations engineers, security professionals, and data scientists should work together with a shared understanding of how their roles contribute to overall business goals.
Set up clear communication channels and regular check-ins to keep everyone aligned. Linking team objectives to specific KPIs ensures that all efforts are focused on measurable outcomes.
A strong DevOps culture, which emphasizes accountability from end to end, is vital here. When AI-driven decisions directly affect system performance and costs, collaboration becomes even more critical.
Even with the power of AI, human oversight remains indispensable for ensuring system reliability and making critical decisions. The idea is to enhance human capabilities, not replace them. While cross-functional collaboration drives deployment, maintaining a human layer to validate AI decisions is key.
Using explainable AI (XAI) models can help engineers understand and verify scaling decisions. For instance, if the system scales up resources during an off-peak period, the team should be able to review and confirm why that decision was made and whether it was appropriate.
Experts stress that human oversight is crucial because automated decision-making still has limitations. High-impact decisions, like significant resource changes or unusual patterns, should trigger manual reviews. Feedback loops can then be used to refine AI models based on real-world results.
Interestingly, recent data shows that DevOps teams using AI are 30% more likely to rate their performance as highly effective. However, over two-thirds of these teams manually review AI outputs at least half the time. Striking the right balance between automation and human input is critical.
To keep predictive scaling effective, continuously monitor AI systems for performance, security, and behavior. Set up alerts for model drift, and ensure regular retraining and validation as application patterns evolve.
When it comes to managing resources efficiently, choosing the right scaling method is a game-changer. Each approach - manual, rule-based, or AI-driven - has its own influence on performance, cost, and complexity.
Manual scaling depends entirely on human intervention, which can lead to delays, especially during unexpected spikes in demand.
Rule-based scaling automates resource adjustments based on predefined thresholds. While it's straightforward and budget-friendly, it struggles to adapt to new scenarios without manual updates.
AI-driven scaling, on the other hand, leverages machine learning to predict workload changes and proactively adjusts resources. This approach is ideal for handling dynamic and unpredictable demands.
Here’s a quick performance snapshot: AI models achieve 92% accuracy in scaling decisions compared to 65% for reactive methods. Additionally, hybrid autoscaling can cut costs by 30% and reduce response times by 65%.
| Scaling Method | Pros | Cons | Use Cases |
|---|---|---|---|
| Threshold-Based | Easy to implement; handles steady workloads well | Slow response; lacks flexibility | Basic web applications |
| Rule-Based | Customizable rules for specific thresholds | Requires manual updates; limited agility | E-commerce and SaaS platforms |
| Predictive (LSTM) | Proactive resource allocation with time-series insights | High resource demands; needs ML expertise | Streaming services, real-time apps |
| Hybrid AI | Combines reactive and predictive capabilities | Complex initial setup | Large-scale enterprise workloads |
Reinforcement learning environments further improve resource efficiency by 25% over rule-based systems. Hybrid autoscaling, which blends predictive models with real-time anomaly detection, not only ensures 99.95% availability but also lowers cloud costs by 30%.
While rule-based systems handle only structured data, AI-driven approaches analyze both structured and unstructured inputs. This capability enables them to account for seasonal trends, user behavior, and even external factors.
AI-driven predictive scaling offers a range of tools, each with its strengths and challenges. Choosing the right one depends on your specific needs and the maturity of your infrastructure.
For example, LSTM networks achieve impressive accuracy, with prediction errors under 10% for diverse workloads. Similarly, AI-enhanced Vertical Pod Autoscalers (VPA) can forecast resource needs up to 45 minutes ahead with 83% accuracy, reducing resource-related incidents by 40%.
However, it’s important to note that predictive scaling demands significant computational power and expertise in machine learning. Despite these challenges, the long-term benefits often outweigh the initial investment. In 2023, 60% of businesses adopted cloud-native technologies, yet 45% reported inefficiencies in auto-scaling operations. This underscores the need for more advanced solutions.
Among these, hybrid AI scaling stands out as the most advanced option. By integrating reactive and predictive models, it delivers exceptional performance and cost savings, making it the go-to choice for large-scale enterprise workloads.
These insights can help you align your scaling strategy with your infrastructure’s needs and workload demands, ensuring efficient and effective resource management.
Shifting from traditional scaling methods to AI-driven predictive scaling takes careful planning and a well-thought-out strategy. When done right, this transition can lead to impressive gains while avoiding common hurdles.
Predictive scaling powered by AI helps lower costs, improve performance, and ensure stable operations by adjusting resources in advance based on expected demand. This proactive method strengthens the flexible, dynamic DevOps approach mentioned earlier. For instance, in the first half of 2024, organizations increased their spending on compute and storage hardware for AI deployments by 97% compared to the previous year, reaching $47.4 billion.
To make the most of predictive scaling, follow these practical steps for a smooth transition:
"Modernization requires readiness in people, technology, and processes." - Microsoft Learn
Adopting predictive scaling shifts operations from being reactive to being strategically proactive. Encourage a culture of learning and collaboration between your AI and cloud teams. Start on a small scale, adapt quickly, and expand systematically as you see measurable results.
"Realize that people are the most important component of the equation." - Gerry Leitao, Vice President of Managed Services Delivery and Platforms, Capgemini
To keep AI-driven predictive scaling models accurate, it's crucial for organizations to regularly retrain these models with updated data. This ensures they stay in tune with shifting workload patterns and can effectively respond to new trends and fluctuations.
Equally important is continuous monitoring and evaluation of the model's performance. By tracking metrics like accuracy, precision, and recall, teams can pinpoint areas that need improvement. Incorporating adaptive auto-scaling techniques, such as dynamic resource allocation, allows systems to adjust seamlessly to real-time workload changes.
When these strategies are combined, organizations can fine-tune their models and maintain dependable performance, even when faced with unpredictable scenarios.
Integrating AI-driven predictive scaling into CI/CD pipelines brings its own set of hurdles. These include dealing with added pipeline complexity, managing large datasets securely, and prioritizing data privacy. It also often calls for a fresh approach to service isolation and trust boundaries to prevent security gaps and ensure consistent operations.
To tackle these issues, teams can focus on a few key strategies: adopting secure data management practices, making incremental changes to minimize risks, and setting up continuous monitoring to keep the pipeline stable. When combined, these steps can make the integration process smoother without compromising security or performance.
Human involvement is crucial when using AI for predictive scaling, as it helps address potential challenges like bias, operational mistakes, or ethical dilemmas that AI might miss. While AI is fantastic at crunching massive datasets and spotting patterns, it falls short in areas requiring nuanced judgment and understanding of context - qualities that human experts bring to the table.
One effective way to achieve this balance is by implementing a human-in-the-loop strategy. This means involving experts to review and validate AI-generated outputs during key decision-making moments, especially in high-stakes or complex situations. By blending the speed and efficiency of AI with human expertise, organizations can maintain systems that are not only accurate and dependable but also ethically sound.
Need an expert team to provide digital solutions for your business?
Book A Free CallDive into a wealth of knowledge with our unique articles and resources. Stay informed about the latest trends and best practices in the tech industry.
View All articlesExplore effective patterns and pitfalls of tenant data isolation in multi-tenant systems to enhance security and compliance.
Jul 30, 2025
Read More
Implement these 10 Quality Assurance steps to enhance the reliability and performance of your SaaS application while minimizing bugs and user abandonment.
May 21, 2025
Read More
AI automation is revolutionizing SaaS performance by optimizing costs, enhancing user experiences, and streamlining operations.
May 15, 2025
Read More
Learn effective strategies to debug third-party API errors and maintain application stability while enhancing user experience.
Jul 30, 2025
Read More
Learn how to successfully launch your SaaS MVP in just 90 days by following these critical steps for validation, development, and iteration.
May 16, 2025
Read More
Learn how to safeguard your API backends against rising Man-in-the-Middle attacks through encryption, authentication, and secure network practices.
Jul 30, 2025
Read More
Choosing between a mobile app and a web app for your SaaS product? Explore key factors like cost, user engagement, and development speed.
May 21, 2025
Read More
Learn best practices for linting React code to improve quality, consistency, and collaboration in your development projects.
Jul 30, 2025
Read More
The IT industry continues to drive innovation and redefine the way businesses operate. In this blog, we explore how IT solutions are transforming industries, enhancing...
May 8, 2025
Read More
When it comes to SaaS (Software as a Service) platforms, one thing is clear: user experience (UX) is everything. At Propellius Technologies, we know that...
May 8, 2025
Read More
Apple faces unprecedented challenges in AI as OpenAI acquires Jony Ive's design team for $6.5B and Google partners with Samsung on Android XR. Can Apple's...
May 22, 2025
Read More
Explore common challenges in SaaS development, including scalability, security, and API integration, along with effective solutions for each.
May 23, 2025
Read More
Learn how to manage concurrency in serverless architectures effectively to enhance performance, reduce costs, and prevent throttling.
Jul 30, 2025
Read More
Trump administration revokes Harvard's ability to enroll international students, impacting 6,800 students and threatening Silicon Valley's talent pipeline. Analysis of implications for US tech leadership.
May 23, 2025
Read More
Explore the top cloud solutions that optimize scalability, security, and cost for modern SaaS architecture, helping businesses thrive in the cloud.
May 23, 2025
Read More
You know how the internet has become such a big part of our lives? Well, the way we use it has changed a lot over...
May 8, 2025
Read More
Learn how staff augmentation can help tech startups save costs, access global talent, and scale teams quickly for efficient growth.
May 26, 2025
Read More
In the digital age, eCommerce has become a cornerstone of the global retail landscape. The low barriers to entry and the promise of reaching a...
May 8, 2025
Read More
Learn how Atomic Design enhances React component organization by breaking down UIs into reusable, scalable pieces while navigating common challenges.
Jun 6, 2025
Read More
AI is revolutionizing how brands communicate. In this article, we dive into how Phrasee, a leader in AI-powered brand language generation, is enabling marketing teams...
Jun 6, 2025
Read More
Effective onboarding of augmented developers in Agile teams boosts productivity and retention through preparation, structured processes, and continuous feedback.
Jun 5, 2025
Read More
Selecting the right tech stack for your MVP is crucial for startup success, impacting costs, scalability, and development speed.
Jun 5, 2025
Read More
Learn key strategies for scaling your SaaS product from MVP to enterprise level, focusing on architecture, performance, security, and cloud optimization.
May 26, 2025
Read More
Explore seven human-centered design principles that can transform your MVP into a user-centric product that resonates and drives success.
Jun 9, 2025
Read More
Optimize memory usage in AI workflows to cut costs and enhance performance with effective strategies and tools for better resource management.
May 29, 2025
Read More
Explore the essential UI/UX best practices for SaaS applications in 2025, focusing on personalization, accessibility, and innovative input methods.
May 26, 2025
Read More
Learn how a 90-day MVP sprint can minimize risk, cut costs, and ensure a successful product launch through rapid validation and user feedback.
May 30, 2025
Read MoreOptimize real-time streaming with effective data compression techniques that reduce latency and enhance performance across various industries.
Jun 17, 2025
Read More
Explore the strengths and weaknesses of Supabase and Firebase for real-time collaboration tools, focusing on scalability, performance, and developer experience.
Jun 6, 2025
Read More
Explore the differences between two leading platforms for MVP scaling, focusing on their database structures, pricing, security, and performance.
Jun 5, 2025
Read More
Learn how Test-Driven Development (TDD) can enhance the reliability and maintainability of React applications through structured testing.
Jun 6, 2025
Read More
Learn how to effectively balance technical debt with innovation to ensure sustainable growth and maintain a competitive edge in your startup.
May 29, 2025
Read More
Learn how to foster a thriving knowledge-sharing culture in remote teams through psychological safety, technology, and effective communication.
Jun 6, 2025
Read More
A complete guide to choosing the right mobile app development company—covering expertise, transparency, UX focus, agile methods, and long-term partnerships to ensure your app succeeds...
Jun 12, 2025
Read More
Explore effective caching strategies for dependency management that enhance build performance and reduce costs in software development.
Jul 29, 2025
Read More
Unlock your system's performance potential by effectively analyzing logs to identify bottlenecks and optimize operations.
Jun 17, 2025
Read More
Explore essential practices for checkpointing in stream processing to ensure data integrity, fault tolerance, and efficient recovery from failures.
Jun 9, 2025
Read More
Learn how to effectively use a popular JavaScript library for mocking and stubbing in tests, enhancing reliability and speed in your development process.
Jun 9, 2025
Read More
Learn how to effectively automate regression testing in CI/CD pipelines to enhance software reliability and speed up development.
Jun 17, 2025
Read More
Learn essential best practices for managing secrets in CI/CD pipelines to protect sensitive data and enhance security against breaches.
Jun 6, 2025
Read More
Explore how Agile roles enhance MVP development by fostering collaboration, speeding up delivery, and ensuring products meet user needs.
Jun 11, 2025
Read More
Explore how manual testing enabled startups to launch high-quality MVPs in just 90 days, ensuring speed without sacrificing user experience.
Jun 6, 2025
Read More
Learn how to effectively scan and fix vulnerabilities in React and Node.js projects to ensure secure applications and safeguard against risks.
Jun 17, 2025
Read More
Agile sprints streamline MVP development, enabling rapid iterations, user feedback integration, and efficient project management for startups.
Jun 17, 2025
Read More
Aligning designers and developers through shared standards and effective collaboration can drastically improve efficiency and product quality.
Jun 11, 2025
Read More
Align your teams for faster MVP sprints by creating a shared vision, setting collaborative KPIs, and leveraging effective workflows.
Jul 29, 2025
Read More
Explore essential best practices for regression testing in DevOps, ensuring software stability and quality amid rapid development cycles.
Jul 29, 2025
Read More
Learn how to create an effective shared knowledge base that enhances team collaboration, boosts productivity, and maintains security.
Jul 30, 2025
Read MoreLearn how to leverage Figma for effective design system collaboration, enhancing team workflows and ensuring consistent design practices.
Jul 30, 2025
Read More
Explore how a financial startup launched a minimum viable product in just 90 days through collaborative prototyping and user feedback.
Jul 29, 2025
Read More
Explore how automated load balancing enhances cloud app performance, reduces costs, and ensures reliability during traffic spikes.
Jul 30, 2025
Read MoreGet in Touch
Let's Make It Happen
Get Your Free Quote Today!

Get in Touch
Let's Make It Happen
Get Your Free Quote Today!

You bring the vision. We handle the build.
